今天小李哥将开启全新的技术分享系列,为大家介绍生成式AI的安全解决方案设计方法和最佳实践。近年来生成式 AI 安全市场正迅速发展。据IDC预测,到2025年全球 AI 安全解决方案市场规模将突破200亿美元,年复合增长率超过30%,而Gartner则预估到2025年约30%的网络攻击将利用生成式AI技术。与此同时,Capgemini的调查显示,近74%的企业认为AI驱动的安全防护至关重要,加上Cybersecurity Ventures报告指出,与生成式AI相关的安全事件年增长率超过20%,这充分表明企业和安全供应商正面临日益严峻的安全挑战,并加大投入以构建更全面的防护体系。今天要介绍的就是如何设计生成式AI应用安全解决方案,抵御OWASP Top 10攻击。未来也会分享更多的AI安全解决方案,欢迎大家关注。  目前我们生活中有各色各样的生成式AI应用,常见的场景之一就是生成式AI对话助手。然而在部署之前,通常还要对应用进行评估,其中包括了解安全态势、监控和日志记录、成本跟踪、弹性等问题。在这些评估中,安全性通常是最高优先级。如果存在无法明确识别的安全风险,我们就无法有效解决这些风向,这可能会阻碍生成式AI应用向生产环境部署的进度。 在本文章中,小李哥将向大家展示一个自己设计的生成式应用的真实场景,并演示如何利用 OWASP安全框架,基于大语言模型应用常见的Top 10安全攻击来评估应用的安全态势,以及实施缓解措施。下图就是一个生成式AI应用的安全解决方案最佳实践,我们将继续从左到右详细介绍本方案中使用到的安全方案细节。 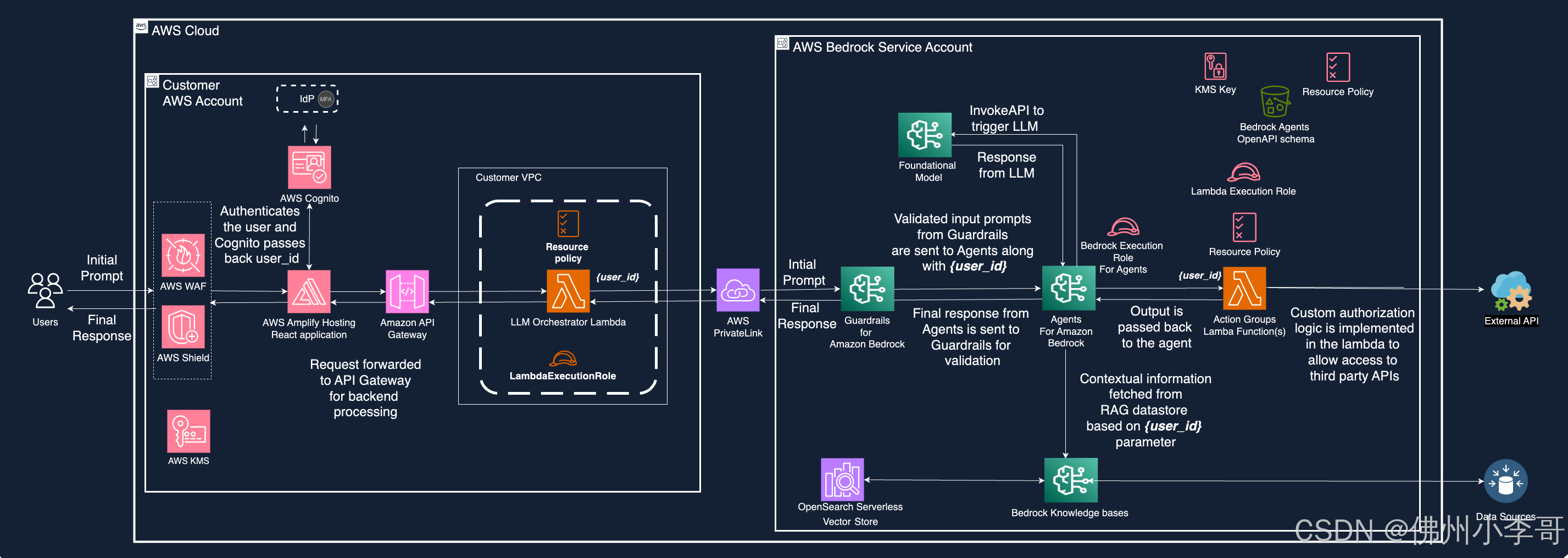 应用控制层 应用层通常容易遭受到诸如LLM01:2025提示注入、LLM05:2025输出处理不当以及LLM02:2025敏感信息泄露等风险。恶意攻击者可能会频繁尝试恶意的提示词输入来操控AI模型,从而可能通过AI模型泄露敏感信息或危及下游的应用系统。 在我们开头的架构图中,应用层的服务器就是亚马逊云科技无服务器计算服务Lambda。它通过从 API Gateway中提取事件的数据部分并进行语法和语义校验,实施严格的输入验证。通过对输入请求进行清洗、应用白名单和需要组织的关键字黑名单,并预定义合法请求的格式和规则进行验证,使用Lambda服务有助于防止LLM01:2025提示注入攻击。此外通过将user_id字段传递到下游应用中,可以使下游应用组件降低敏感信息泄露的风险,从而解决了LLM02:2025敏感信息泄露的问题。 同时亚马逊云科技Bedrock Guardrails提供了额外的大模型输入输出保护层,可过滤和拦截敏感内容,如个人身份信息(PII)以及通过正则表达式定义的自定义敏感数据。Guardrails还有检测和屏蔽攻击性语言、竞争对手名称或其他不希望出现的词语,确保输入和输出均安全。大家还可以利用 Guardrails在有害或操控性的提示词到达AI模型之前就进行检测和过滤,从而防止LLM01:2025提示注入攻击,维护提示词的完整性。 另一个关键的安全方面是管理AI模型的输出。由于AI模型可能生成包含可执行代码的内容,比如 JavaScript或Markdown,如果这些内容处理不当,就存在XSS攻击的风险。为降低此类风险,我们需要使用输出编码技术,例如HTML实体编码或JavaScript转义,在将内容呈现给用户前将任何潜在有害内容进行无害化转换。此方法解决了LLM05:2025输出处理不当的风险。 我们也可以利用亚马逊云科技Bedrock的提示管理和版本控制,使得在不断提升用户体验的同时,也能维持整个应用的安全性。通过完善管理提示词及其处理方式的变更,在增强IA模型功能的同时不会引入新的漏洞,并降低LLM01:2025提示注入攻击的风险。 降低未经授权或非预期的AI模型操作风险的策略的核心就是:“将AI模型视为不受信任的信息来源,并在某些操作上采用人工介入流程”。 亚马逊云科技Bedrock大语言模型与代理层 AI模型与AI模型代理层经常处理与AI模型的交互,面临诸如LLM10:2025不受限制的使用、LLM05:2025输出处理不当以及LLM02:2025敏感信息泄露等风险。 拒绝服务(DoS)攻击可能会通过大量资源密集型请求使AI模型处理不堪重负,从而降低整体服务质量并增加成本。在与亚马逊云科技Bedrock托管的AI模型交互时,设置诸如输入请求的最大长度等请求参数,将有助于降低AI模型资源耗尽的风险。此外亚马逊云科技Bedrock代理对队列中的最大动作数量以及完成客户意图的总动作数都有硬性限制,这限制了系统对AI模型代理基于用户需求所采取的总动作数量,避免了可能耗尽AI模型资源的异常死循环或密集任务。 输出处理不当会导致远程代码执行、跨站脚本(XSS)、服务器端请求伪造(SSRF)以及权限提升等安全漏洞。对AI模型生成的输出在发送到下游服务前,如果验证和管理不佳,就可能间接开放漏洞攻击面,让这些漏洞有机可乘。为降低这一风险,应将模型视为普通的应用用户一样,对 LLM生成的响应进行安全验证。亚马逊云科技Bedrock Guardrails利用可配置阈值的内容过滤器来过滤各种有害内容,并在这些响应被其他后端系统进一步处理之前就进行阻拦,从而简化了这一过程。Guardrails会自动评估用户输入和模型响应,检测并帮助防止有害的内容。 亚马逊云科技Bedrock代理在执行多步骤任务时,与亚马逊云科技原生服务以及外部的第三方服务安全集成,从而有效解决输出处理不安全、过量代理行为和敏感信息泄露的风险。在文章开头的架构图中,代理下的action group中的Lambda服务用于对所有输出文本进行编码,使其自动无法被 JavaScript或Markdown异常执行。此外action group中的Lambda函数会解析和记录代理每一步执行时从AI模型得到的回复,并根据恢复内容相应地控制输出,确保在下一步处理前输出内容完全安全。 敏感信息泄露是AI模型面临的另一大风险,因为恶意的提示工程可能会导致AI模型无意中在响应中泄露不该公开的细节,从而引发AI模型隐私和机密性问题。为缓解这一问题,可以通过亚马逊云科技 Bedrock Guardrails中的内容过滤器实施数据清洗措施。 另外还应根据user_id实施自定义、精细化的数据过滤策略,并根据id执行严格的用户访问策略。亚马逊云科技Bedrock Guardrails可以过滤敏感内容,亚马逊云科技Bedrock代理则通过允许大家在预处理输入的提示词模板和处理响应的提示词模板中实施自定义逻辑来去除任何非预期的有害信息,进一步降低了敏感信息泄露的风险。如果大家已为AI模型启用了模型调用日志记录,或者在应用中实施了自定义日志逻辑,将 AI模型的输入和输出记录到亚马逊云科技CloudWatch中,那我们也需要开启CloudWatch日志数据保护等措施,在CloudWatch日志中识别和屏蔽敏感信息,从而进一步降低敏感信息泄露的风险。
|