|
用蓝耘智算平台硬核部署 DeepSeek 后,我太惊喜了!它计算能力超强,快速完成模型训练。资源能灵活调配,不浪费。部署稳,技术支持也及时。这一组合解锁了 AI 无限潜能,让我探索 AI 之路更顺;此后麻麻再也不用担心我不会数学题了;有了蓝耘智算平台部署 DeepSeek后;我一口气都能吃五六个圆锥曲线了!!!   目录 一·DeepSeek认识: 1.1 模型版本与参数规模: 1.2 技术创新点: 1.3 性能表现: 1.4 应用场景: 1.5 开源与商用: 二·蓝耘智算平台助力新时代AI: 2.1蓝耘智算平台核心特性: 2.2蓝耘智算平台应用: ①人工智能与科研创新: ②大数据与行业决策: ③工业制造与教育发展: 三· 蓝耘智算平台如何硬核部署DeepSeek: 一·DeepSeek认识:DeepSeek 是 DeepSeek Cognition 公司推出的一系列涵盖大语言模型与代码模型的 AI 模型。该公司秉持 “用认知智能解锁无限可能” 的理念,致力于打造具有卓越性能和广泛适用性的人工智能解决方案。DeepSeek 旨在通过深度的认知智能,为各个领域提供强大的语言处理和代码生成能力。 1.1 模型版本与参数规模:语言模型:有 7B 和 67B 两种参数规模。7B 版本参数量相对较小,更适合资源受限但仍需一定语言处理能力的场景,能在保证一定性能的同时降低对计算资源的需求;67B 版本则具备更强大的语言理解和生成能力,能够处理复杂的语言任务,生成高质量的文本内容。 代码模型:同样提供 7B 和 33B 两个版本。7B 代码模型可用于日常简单代码的生成和辅助编程,对于一些小型项目和快速迭代的开发场景较为适用;33B 代码模型则在代码生成的准确性、复杂度处理以及对多种编程语言的支持上表现更优,适合大型项目开发和复杂算法的实现。 1.2 技术创新点:全量数据混合训练:DeepSeek 在训练过程中采用全量数据混合训练的方式,将通用文本数据与代码数据进行融合。这种创新的训练策略使得模型能够同时学习到自然语言和代码语言的模式和规律,不仅增强了模型在不同领域的通用性,还提高了模型的整体性能。 长上下文处理能力:通过技术优化,DeepSeek 具备出色的长上下文处理能力。它能够理解和处理长达 16K 长度的上下文信息,这使得模型在处理长篇文档、复杂对话以及需要大量背景知识的任务时表现更为出色,能够更好地把握语义和逻辑关系。 1.3 性能表现:基准测试成绩优异:在多个权威的自然语言处理基准测试中,如 MMLU(大规模多任务语言理解)、GSM8K(小学数学问题)等,DeepSeek 取得了领先的成绩。这表明该模型在语言理解、知识推理和问题解决等方面具有强大的能力,能够准确理解和处理各种类型的自然语言问题。 代码生成质量高:在代码生成任务中,DeepSeek 能够根据用户的需求生成高质量、可运行的代码。它支持多种主流编程语言,如 Python、Java、C++ 等,并且生成的代码具有良好的结构和可读性,能够显著提高开发效率。 1.4 应用场景:智能写作:可以用于各种类型的文本创作,如新闻报道、小说创作、文案撰写等。它能够根据用户提供的主题和要求,生成富有逻辑性和连贯性的文本内容,为内容创作者提供灵感和辅助。 智能客服:在智能客服系统中,DeepSeek 能够准确理解用户的问题,并提供准确、详细的回答。它可以处理复杂的客户咨询,提高客户服务的效率和质量,减少人工客服的工作量。 代码开发:在软件开发领域,DeepSeek 可以作为开发者的智能助手,帮助他们快速生成代码、调试程序和解决技术难题。它能够理解代码上下文,提供代码补全、代码解释和代码优化等功能,提高开发效率和代码质量。 知识问答:在知识问答系统中,DeepSeek 可以作为知识库的智能查询引擎,为用户提供准确的知识答案。它能够处理各种领域的知识问题,帮助用户快速获取所需的信息。 1.5 开源与商用:开源策略:DeepSeek 采取了开源的策略,将部分模型权重和代码开放给社区。这一举措促进了学术研究和技术交流,使得更多的研究人员和开发者能够基于 DeepSeek 进行二次开发和创新,推动了自然语言处理和人工智能领域的发展。 商用支持:除了开源部分,DeepSeek 也为企业和商业用户提供了商用版本和相关的技术支持。企业可以根据自身的需求,选择合适的模型版本和服务方案,将 DeepSeek 应用于实际的业务场景中,实现业务的智能化升级。 二·蓝耘智算平台助力新时代AI:蓝耘智算平台是一款聚焦于人工智能领域,专为满足大规模、高复杂度计算需求而精心打造的综合性解决方案。它整合了先进的硬件设施、高效的软件系统以及智能化的管理工具,旨在为科研机构、企业等各类用户提供一站式的智能计算服务,助力其在人工智能、大数据分析、科学研究等多个领域实现快速创新与突破。 2.1蓝耘智算平台核心特性:①强大计算能力:配备高性能计算集群,含大量先进 GPU 和 CPU,浮点运算能力强,能快速完成复杂深度学习模型训练中的大量矩阵运算与数据处理,有效缩短训练时间。 ②灵活资源配置:支持按需自由选择计算资源,包括 GPU 数量、CPU 核心数、内存大小等。可动态调整资源,适应不同规模项目需求,避免资源浪费或不足。 ③先进分布式计算:采用分布式计算技术,将复杂任务分解并行处理,提高计算效率。具备容错性,部分节点故障时可自动重新分配任务,还能通过添加节点扩展计算能力。 ④安全数据管理:运用多层次数据加密保障传输和存储安全,有完善备份与恢复机制,定期备份数据并可快速恢复。严格的访问控制和权限管理,保护数据隐私。 ⑤易用操作界面:提供直观界面,方便用户提交、监控和管理计算任务。有详细任务状态和资源使用统计,支持批量任务处理与自动化脚本执行,还为专业人士提供 API 接口。 2.2蓝耘智算平台应用:①人工智能与科研创新:蓝耘智算平台为人工智能研发提供全方位支持。在模型训练上,为计算机视觉、自然语言处理等加速赋能,推动快速迭代;助力算法优化与新算法探索,通过大量实验模拟,提升性能、激发创新,还为物理、化学、生命科学等科研领域的模拟与数据分析提供强大算力,推动前沿研究突破。 ②大数据与行业决策:于大数据分析方面,蓝耘智算平台展现强大实力。在商业领域,分析市场和用户数据辅助精准决策;金融场景中,处理交易和信用数据实现风险预警;医疗行业里,分析病历与影像数据助力疾病诊疗,为各行业提供数据驱动的决策依据。 ③工业制造与教育发展:在工业制造领域,蓝耘智算平台推动产品设计优化,通过虚拟模拟降低成本、缩短周期,同时实现生产线数据实时分析,提升智能制造水平。教育场景中,支撑在线教育的考试评分与智能辅导,提供个性化学习体验,也辅助师生开展学术研究与实践活动。 三· 蓝耘智算平台如何硬核部署DeepSeek:首先进行账号注册,传送门: https://cloud.lanyun.net//#/registerPage?promoterCode=0131  注册完后;邮箱信封点击激活。  直接登录:  进入应用市场选第一个进行部署: 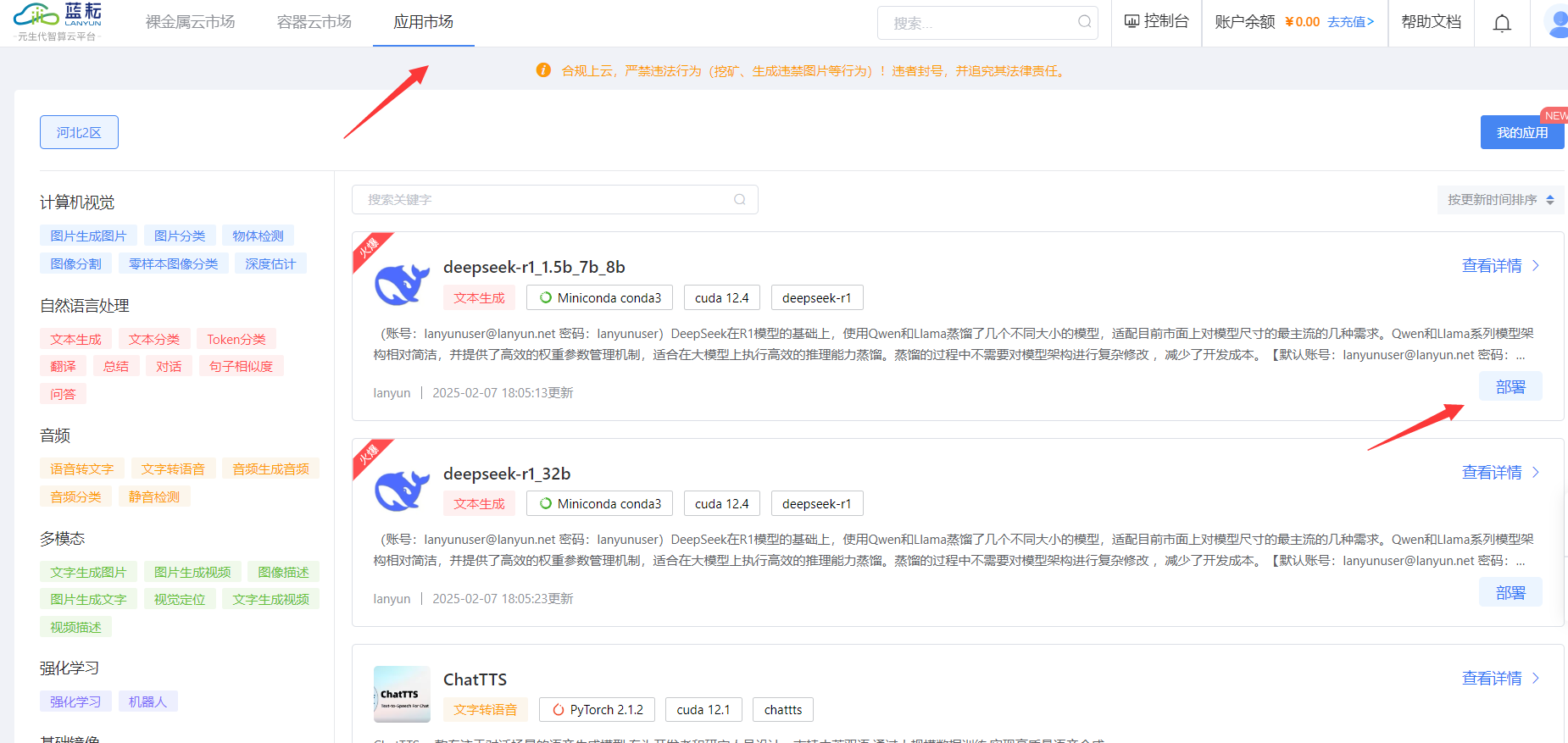 使用注册送的代金券进行购买: 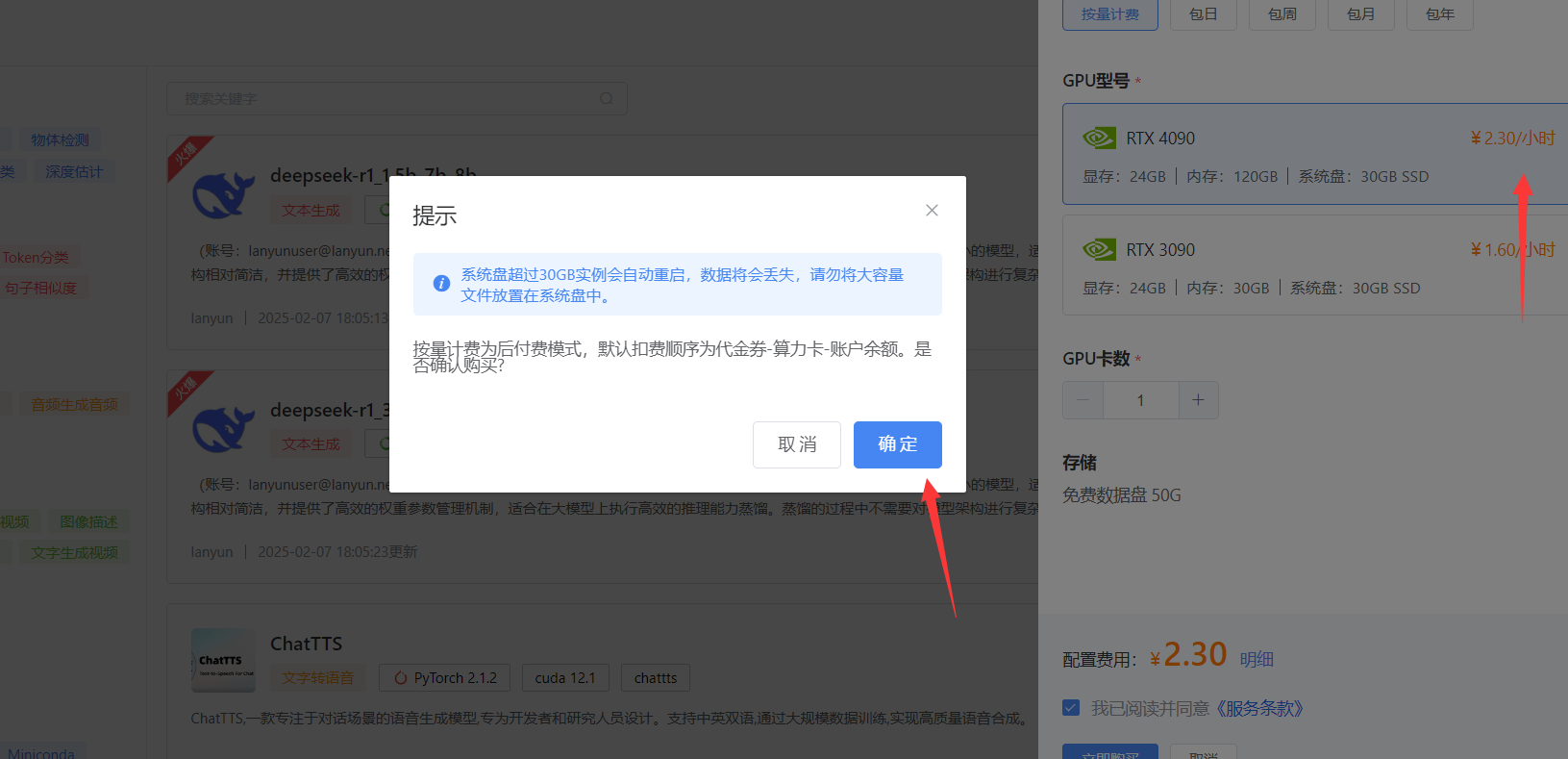 购买成功直接启动: 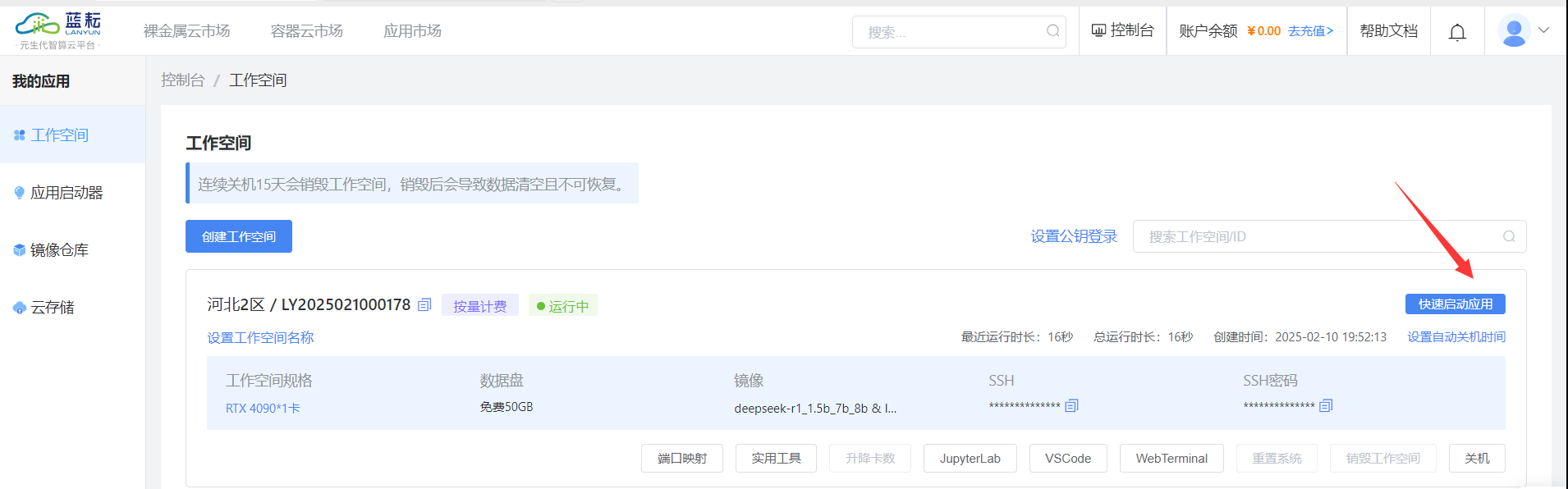 默认登录: 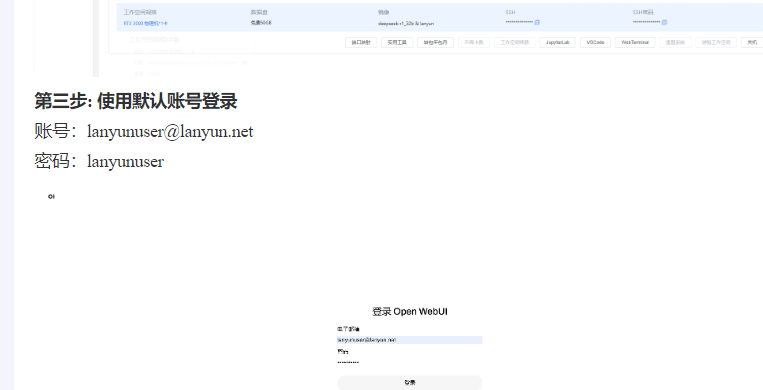 登入后;直接可以使用: 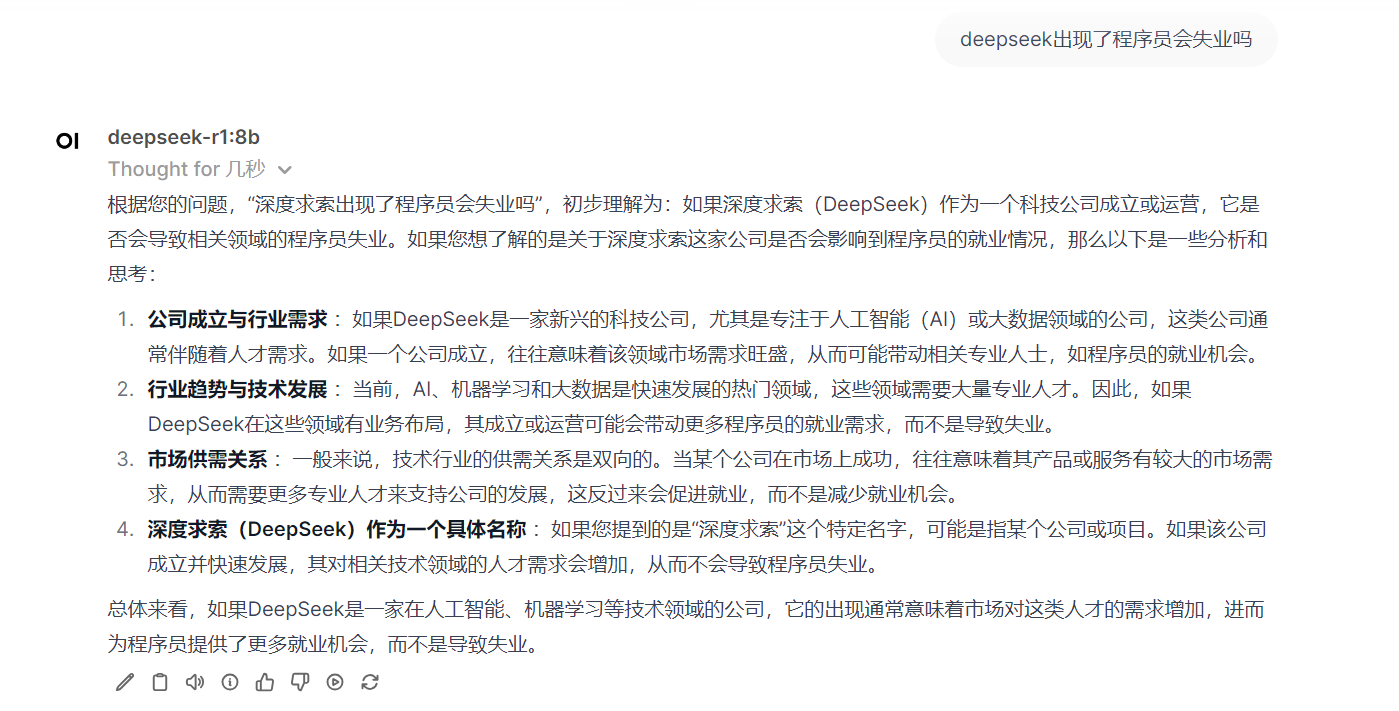 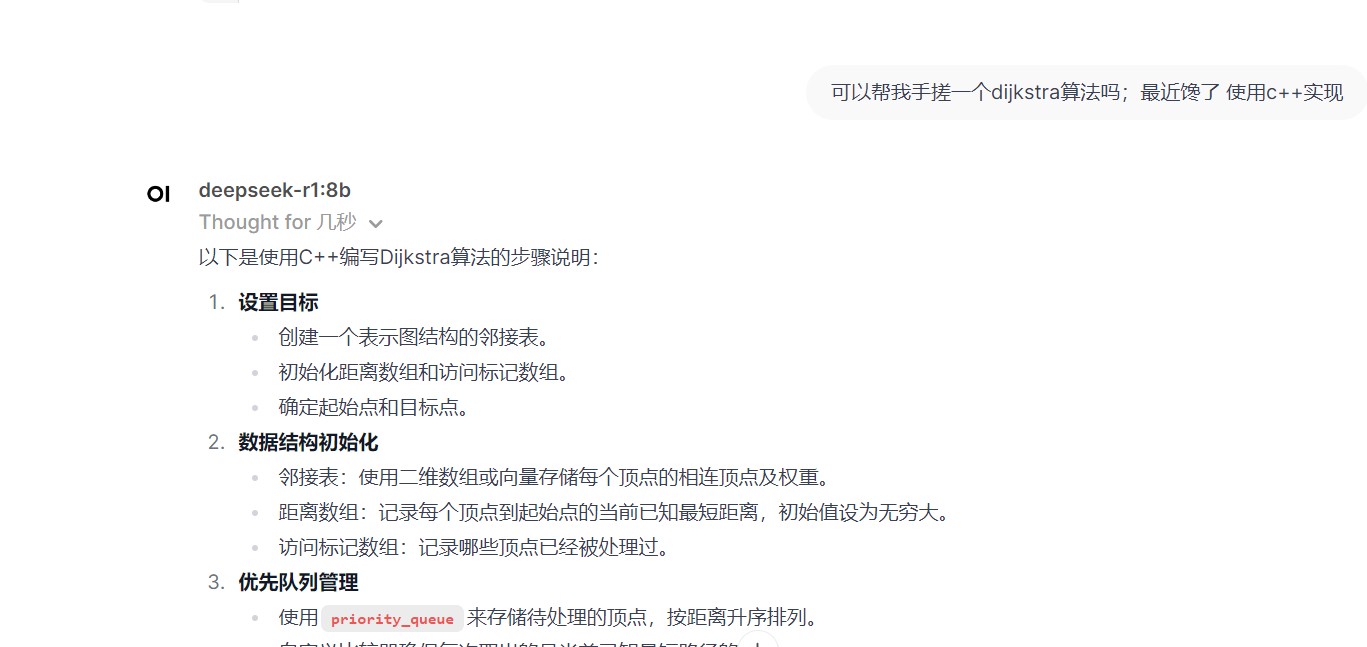 四·蓝耘智算平台如何实现Deepseek调用:前提条件:
实现步骤和示例代码:1. 分析 API 文档:蓝耘智算平台会提供关于调用 DeepSeek 模型的详细 API 文档,其中会包含 API 的端点 URL、请求参数、请求头信息、响应格式等内容。你需要仔细阅读该文档,了解具体的调用要求。 2. 编写代码发送请求:以下是一个使用 Python 语言调用 DeepSeek 模型的示例代码: [code]import requests import json # 替换为你从蓝耘智算平台获取的 API 密钥 API_KEY = "your_api_key" # 替换为蓝耘智算平台提供的 DeepSeek 模型 API 端点 URL API_URL = "https://your-api-url.com" # 请求头信息,通常需要包含 API 密钥 headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" } # 请求参数,根据 API 文档进行调整 data = { "input_text": "请输入你要让模型处理的文本", # 其他可能的参数,如最大生成长度、温度等 "max_length": 200, "temperature": 0.7 } try: # 发送 POST 请求 response = requests.post(API_URL, headers=headers, data=json.dumps(data)) # 检查响应状态码 if response.status_code == 200: # 解析响应的 JSON 数据 result = response.json() print("模型生成结果:", result.get("output_text")) else: print(f"请求失败,状态码:{response.status_code},错误信息:{response.text}") except requests.RequestException as e: print(f"请求发生异常:{e}") [/code]
使用感悟:当我用蓝耘智算平台成功部署完 DeepSeek 后,内心满是震撼与感激。以前,自己尝试部署模型时,就像在黑暗中摸索,复杂的流程和高昂的成本让人望而却步。但蓝耘智算平台就像一座明亮的灯塔,为我照亮了前行的路。 它的计算能力简直太强大了!原本我预估 DeepSeek 模型的训练可能要花费好几天时间,结果在蓝耘智算平台上,短短不到几分钟就完成了大部分训练,速度提升得超乎想象。 这就好比原本是骑着自行车在泥泞道路上艰难前行,突然换成了乘坐高铁,一路风驰电掣。 资源配置的灵活性也让我惊喜不已;比如: 我可以根据不同阶段的需求,自由地调整 GPU、CPU 等资源。就像搭积木一样,想怎么组合就怎么组合,再也不用担心资源不够或者浪费的问题了。这种个性化的服务,让我感觉平台就是专门为我量身打造的。 还有平台的稳定性,就像一座坚固的城堡。在整个部署和训练过程中,没有出现过一次崩溃或者数据丢失的情况,让我可以完全放心地把任务交给它。 这让我有更多的精力去专注于模型的优化和创新;真的太感谢蓝耘智算平台了,它让我在人工智能的探索道路上迈出了坚实的一步,也让我对未来的研究充满了信心。 冲冲冲: https://cloud.lanyun.net//#/registerPage?promoterCode=0131 免责声明:本内容来源于网络,如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |











