 一、引言pipeline(管道)是huggingface transformers库中一种极简方式使用大模型推理的抽象,将所有大模型分为音频(Audio)、计算机视觉(Computer vision)、自然语言处理(NLP)、多模态(Multimodal)等4大类,28小类任务(tasks),共计覆盖32万个模型。 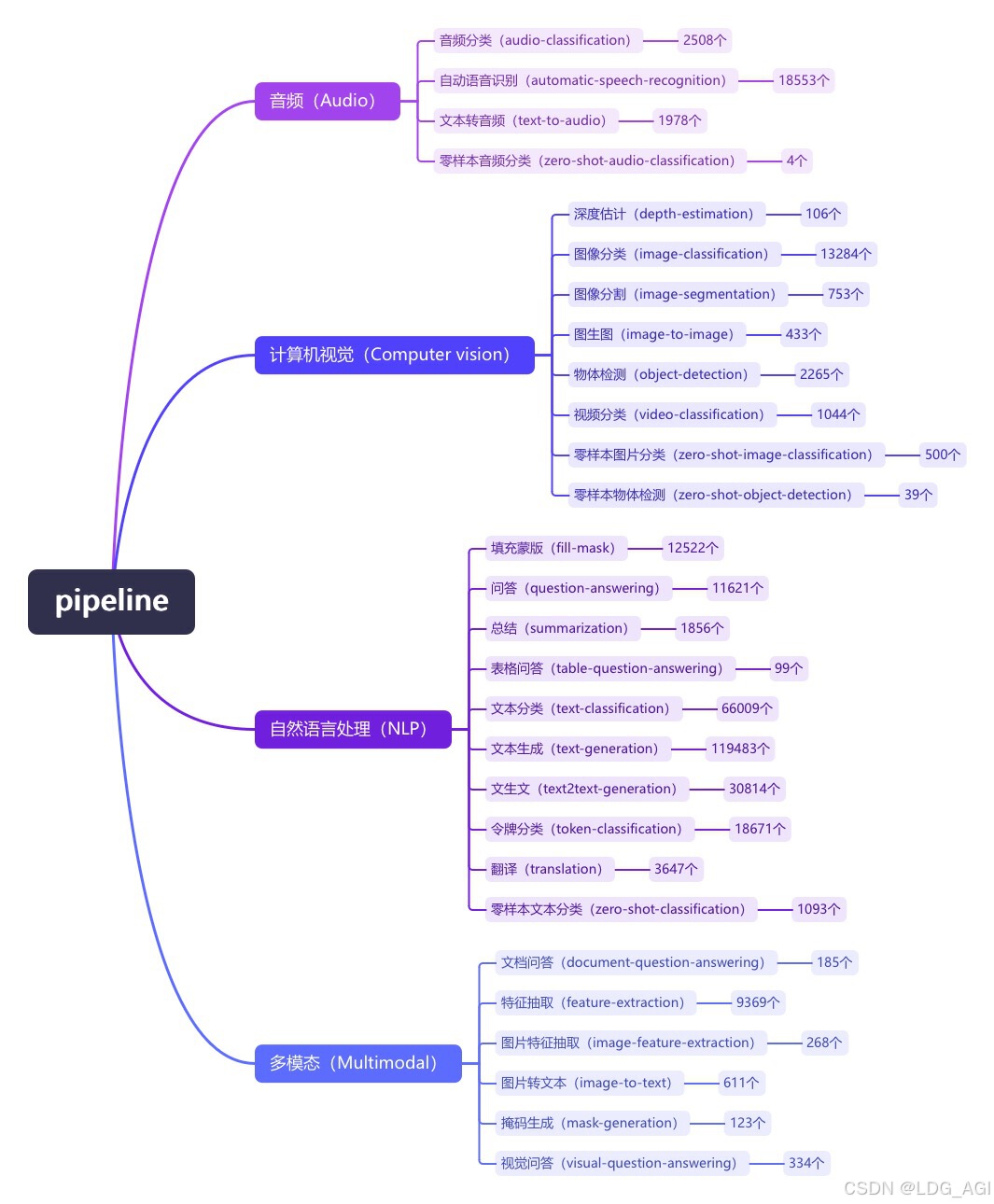 今天介绍Audio的第三篇,文本转音频(text-to-audio/text-to-speech),在huggingface库内共有1978个音频分类模型,其中1141个是由facebook生成的不同语言版本,其他公司发布的仅有837个。 二、文本转音频(text-to-audio/text-to-speech)2.1 概述文本转音频(TTS),与上一篇音频转文本(STT)是对称技术,给定文本生成语音,实际使用上,更多与语音克隆技术相结合:先通过一段音频(few-show)进行声音克隆,再基于克隆的音色和文本生成语音。应用场景极多,也是人工智能领域最易看到成果的技术,主要应用场景有读文章、音乐生成、短视频智能配音、游戏角色智能配音等。 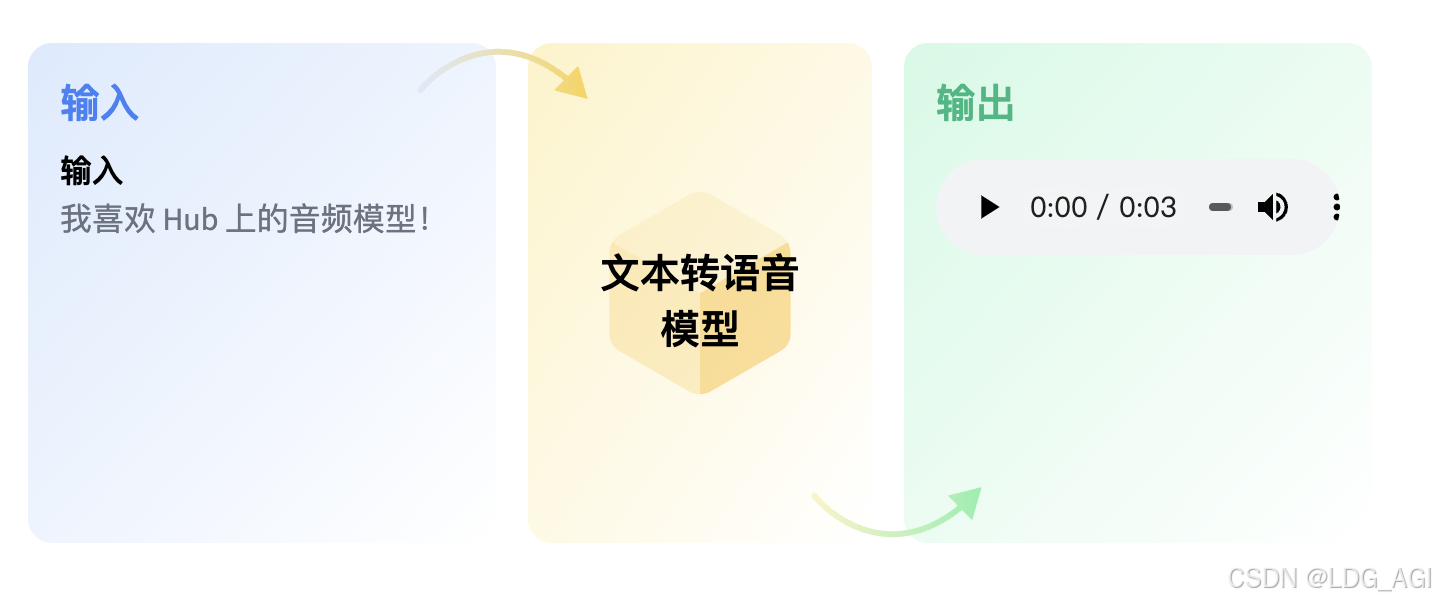 2.2 技术原理2.2.1 原理概述当前比较流行的做法还是基于transformer对文本编码与声音编码进行对齐,声音方面先产生一个对数梅尔频谱图,再使用一个额外的神经网络(声码器)转换为波形。 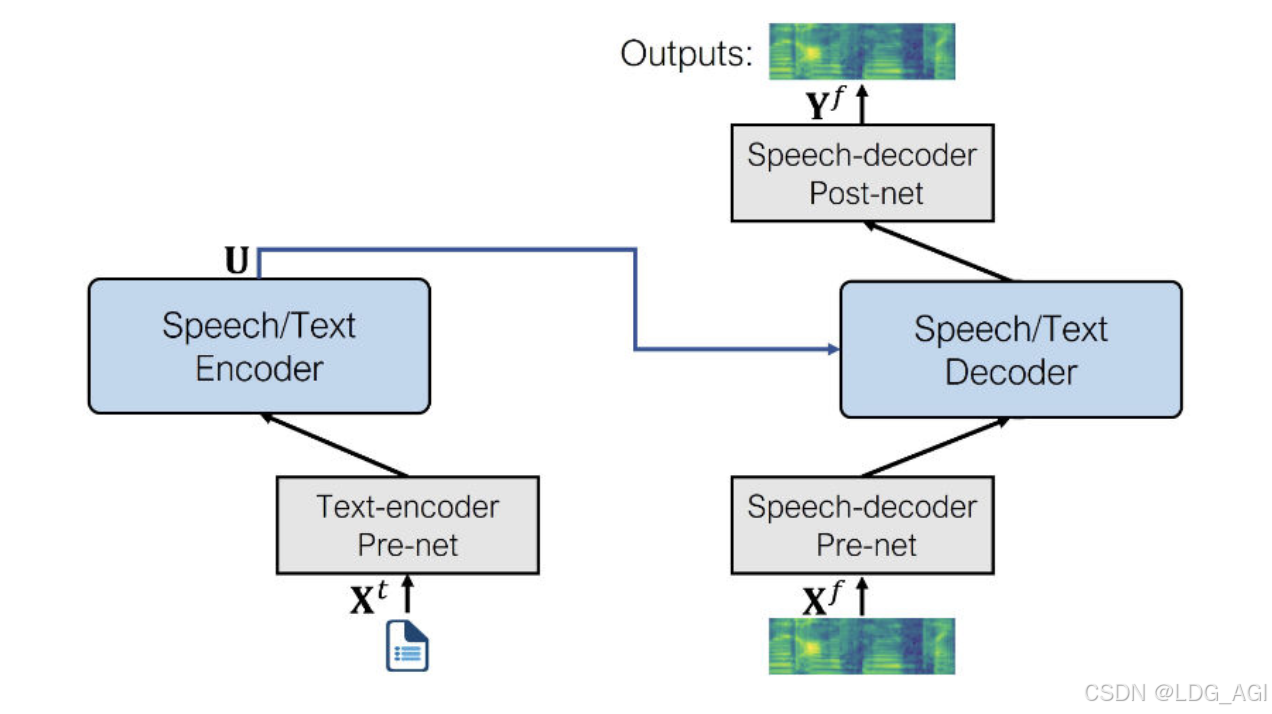 模型类别上,以suno/bark为代表的语音生成和以xtts为代表的声音克隆+语音生成各占据半壁江山,使用比较多的模型如下 2.2.2 语音生成(zero-shot)
2.2.3 声音克隆+语音生成(few-shot)
2.3 pipeline参数2.3.1 pipeline对象实例化参数( *args, vocoder = None, sampling_rate = None, **kwargs )2.3.2 pipeline对象使用参数
2.3.3 pipeline对象返回参数
2.4 pipeline实战2.4.1 suno/bark-small(默认模型)pipeline对于text-to-audio/text-to-speech的默认模型是suno/bark-small,使用pipeline时,如果仅设置task=text-to-audio或task=text-to-speech,不设置模型,则下载并使用默认模型。 [code]import os os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" os.environ["CUDA_VISIBLE_DEVICES"] = "2" import scipy from IPython.display import Audio from transformers import pipeline pipe = pipeline("text-to-speech") result = pipe("Hello, my dog is cooler than you!") sampling_rate=result["sampling_rate"] audio=result["audio"] print(sampling_rate,audio) scipy.io.wavfile.write("bark_out.wav", rate=sampling_rate, data=audio) Audio(audio, rate=sampling_rate)[/code]可以将文本转换为语音bark_out.wav。 bark支持对笑声、男女、歌词、强调语气等进行设定,直接在文本添加:
同时,pipeline可以指定任意的模型,模型列表参考TTS模型库。 2.4.2 coqui/XTTS-v2语音克隆参考官方文档:可以使用python或命令行2种方式轻松使用model_list内的模型,优先要安装TTS的pypi包: [code]pip install TTS -i https://mirrors.cloud.tencent.com/pypi/simple[/code]2.4.2.1 语音转换(参考语音,将语音生成语音) python版本: [code]import torch from TTS.api import TTS # Get device device = "cuda" if torch.cuda.is_available() else "cpu" # List available 🐸TTS models print(TTS().list_models()) # Init TTS tts = TTS(model_name="voice_conversion_models/multilingual/vctk/freevc24", progress_bar=False).to("cuda") tts.voice_conversion_to_file(source_wav="my/source.wav", target_wav="my/target.wav", file_path="output.wav")[/code]命令行版本: [code]tts --out_path ./speech.wav --model_name "tts_models/multilingual/multi-dataset/xtts_v2" --source_wav "./source_wav.wav" --target_wav "./target_wav.wav"[/code]2.4.2.2 文字转语音(参考语音,将文字生成语音) python版本: [code]import torch from TTS.api import TTS # Get device device = "cuda" if torch.cuda.is_available() else "cpu" # List available 🐸TTS models print(TTS().list_models()) # Init TTS tts = TTS("tts_models/multilingual/multi-dataset/xtts_v2").to(device) # Run TTS # ❗ Since this model is multi-lingual voice cloning model, we must set the target speaker_wav and language # Text to speech list of amplitude values as output wav = tts.tts(text="Hello world!", speaker_wav="my/cloning/audio.wav", language="en") # Text to speech to a file tts.tts_to_file(text="Hello world!", speaker_wav="my/cloning/audio.wav", language="en", file_path="output.wav") tts = TTS("tts_models/de/thorsten/tacotron2-DDC") tts.tts_with_vc_to_file( "Wie sage ich auf Italienisch, dass ich dich liebe?", speaker_wav="target/speaker.wav", file_path="output.wav" )[/code]命令行版本: [code]$ tts --text "Text for TTS" --model_name "2.5 模型排名在huggingface上,我们筛选自动语音识别模型,并按近期热度从高到低排序: 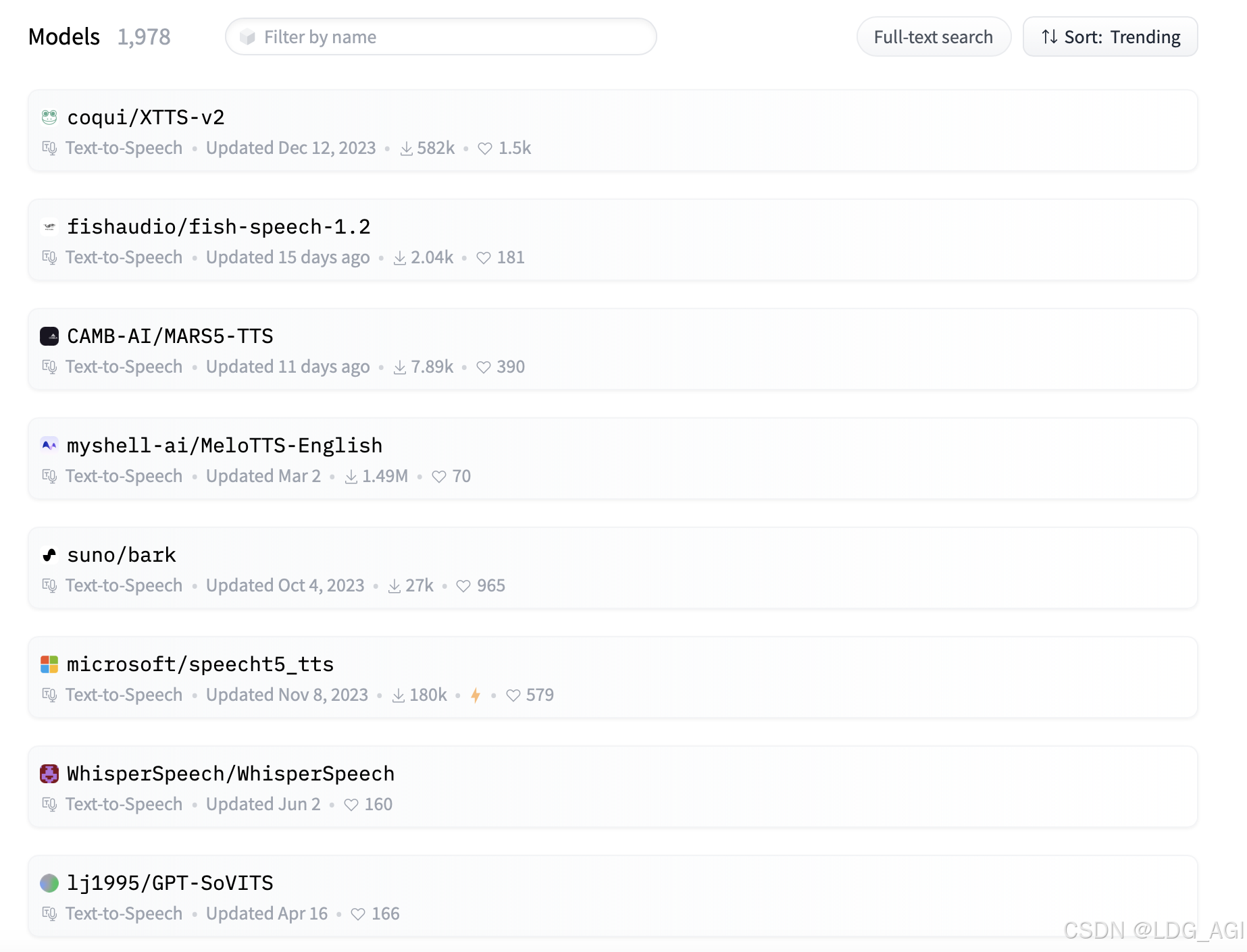 看起来有1978个,实际上有1141是由facebook生成的不同语言版本,其他公司发布的仅有837个:  三、总结本文对transformers之pipeline的文本生成语音(text-to-audio/text-to-speech)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline以及tts的python和命令行工具完成文字生成语音、文字参考语音生成语音、语音参考语音生成语音,应用于有声小说、音乐创作、变音等非常广泛的场景。 |











